Seedfinder Review for 24 Karat From Dna Genetics
Introduction
Humans accept a long history with Cannabis sativa, with show of cultivation dating back as far as 10,000years (Abel, 2013). The World Health System reports Cannabis as the most widely cultivated, trafficked and driveling illicit drug, and it constitutes over half of worldwide drug seizures (World Wellness System, 2018). The United States is currently experiencing drastic changes in patterns of Cannabis utilise associated with widespread relaxation of laws that previously limited both medical and recreational consumption (Cousijn et al., 2018), as well as hemp cultivation. This has led to a demand for all-encompassing research into the basic biology and taxonomy of Cannabis sativa (Hillig, 2005; Clarke and Merlin, 2013; Lynch et al., 2016; Vergara et al., 2016; Small, 2017).
Cannabis sativa is the just described species in the genus Cannabis (Cannabaceae) but there are several unremarkably described subcategories that are widely recognized. There are two primary groups, which are well-supported by genetic analyses (Sawler et al., 2015; Lynch et al., 2016; Dufresnes et al., 2017; Soler et al., 2017): (1) hemp or hemp type which is legally divers in the Usa equally Cannabis containing no more than 0.3% THC, and (ii) marijuana, drug type, or drug blazon which encompasses all Cannabis with THC concentrations >0.iii% THC. The term marijuana is controversial, then unless referencing "research grade marijuana" as divers by the US government, we utilize the term "drug type," as in that location is no adequate widely used term for Cannabis that does not classify as hemp. It is important to note that much of the confusion around Cannabis groups is related to the fact that hemp and drug types are distinguished based on % THC content, which is a variable trait that has been selected for or confronting in the two groups. Hemp types tend to have higher concentrations of CBD than drug types (de Meijer et al., 1992). High THC drug types more often than not contain >12% THC and average ~10–23% THC in dispensaries (Potter et al., 2008; Vergara et al., 2017; Jikomes and Zoorob, 2018). Within the two major groups, Cannabis can be further divided into varietals or strains. Loftier THC drug types are frequently categorized farther in the commercial market: Sativa, Indica, and Hybrid strains, which reportedly have unlike intoxicating furnishings (Heilig, 2011; Hazekamp and Fischedick, 2012; Smith, 2012; McPartland, 2017; Leafly, 2018). There is continuing debate among experts surrounding the advisable taxonomic treatment of Cannabis groups, which is confounded by vernacular usage of these terms vs. what researchers suggest is more appropriate nomenclature (Small et al., 1976; Emboden, 1977, 1981; Clarke and Merlin, 2015; Small, 2015, 2016; McPartland, 2017; McPartland and Guy, 2017). Genetic analyses have not shown clear and consequent differentiation amongst the three ordinarily described high THC drug strain categories (Sawler et al., 2015; Lynch et al., 2016), but both the recreational and medical Cannabis communities maintain that there are distinct differences in furnishings between Sativa and Indica strains (Smith, 2012; Leafly, 2018).
Although Cannabis has been federally controlled in the The states since 1937, as of February 2021, 36 states and the District of Columbia (DC) allow regulated medical use, and 16 states and Washington DC permit adult recreational utilise (ProCon, 2018a). All the same, because the DEA lists THC as a Schedule I substance (Usa Congress, 1970), enquiry on all aspects of this institute has been limited. In the U.s., a Schedule I substance is described as a drug with no accepted medical use and a loftier potential for abuse (United states of america Congress, 1970). Surgeon General Jerome Adams recently expressed concern that the current scheduling in the most restrictive category is inhibiting research on Cannabis as a potentially therapeutic plant (Jaeger, 2018). The Academy of Mississippi, funded through the National Institutes of Wellness/National Establish on Drug Abuse (NIH/NIDA), currently holds the but license issued by the Drug Enforcement Administration (DEA) for the cultivation of Cannabis for research purposes (Drug Enforcement Administration and Section of Justice, 2016). As such, NIDA serves as the sole legal provider of drug-blazon Cannabis for federally funded medical research in the United States. NIDA does non abound or distribute hemp-blazon Cannabis.
Medical research on Cannabis has primarily focused on isolated THC and CBD (Borgelt et al., 2013; Maa and Figi, 2014; Backes and Weil 2014; National Plant on Drug Corruption, 2016a, 2019, 2020; Baron, 2018; Citti et al., 2018; Cousijn et al., 2018) but there are hundreds of other chemical constituents in Cannabis (ElSohly, 2007), including cannabinoids and terpenes (Businesswoman, 2018). Recent enquiry has documented that NIDA-provided Cannabis has distinctly different cannabinoid profiles than commercially available Cannabis (Vergara et al., 2017). Specifically, Vergara et al. (2017) found that NIDA-reported THC and CBD concentrations were only 27 and 48%, respectively, of the mean values of commercially available drug-type Cannabis samples in the four U.s.a. cities (Vergara et al., 2017). Due to the growing evidence that chemical constituents in various combinations and abundances in the whole plant work in concert to create the suite of reported physiological furnishings (Baron, 2018; Nahler et al., 2019; Russo, 2019; Ferber et al., 2020), it is important to know how strains vary in all relevant components. The chemical makeup of each variant of Cannabis is influenced by environmental conditions (e.g., light, water, nutrients, soil, airflow, etc.) and the underlying genetic makeup. Since genotype does not change, genetic data is essential baseline information for agreement Cannabis multifariousness, consistency, and potential furnishings.
In the current study, we investigated the genetic relationship of two types of NIDA-obtained Cannabis to commercially bachelor drug-type Cannabis, as well as wild (feral) and cultivated hemp. Since Cannabis has been nether heavy bogus pick for different traits such as THC content or industrial uses, nosotros focused solely on genetic data. Nosotros assessed ten variable nuclear microsatellite loci targeting non-coding regions of the genome to examine genetic differentiation among our samples independent of recent human selection. Included in the nowadays study were samples from NIDA (high THC and high THC/CBD), loftier THC drug type, low THC/loftier CBD drug type, wild growing hemp (presumed escapees from tillage), and cultivated hemp. This study aimed to investigate where enquiry form Cannabis supplied past NIDA falls on the genetic spectrum of Cannabis groups.
Materials and Methods
Cannabinoid concentrations were non measured for any of the samples, as this was a genetic report. Samples were categorized based on the information provided at the fourth dimension of conquering. A total of 49 Cannabis samples acquired in the United States were used in this enquiry (Supplementary Table i), including Wild (feral) hemp (6), Cultivated hemp (3), NIDA samples (2), high CBD drug type (3), and high THC drug type (35). The wild nerveless hemp was sampled from herbaria collections and is presumed to represent feral specimens that escaped from cultivation. NIDA "enquiry class marijuana" was express to two samples obtained via another study: "high THC" defined by NIDA equally containing >5–x% THC (RTI log number 13494-22, reference number SAF 027355) and "high THC/CBD" divers by NIDA as containing 5–x% of both THC and CBD (RTI log number 13784-1114-18-six, reference number SAF 027355: National Found on Drug Abuse, 2016b). NIDA has express the access of "research course marijuana" for not-medical inquiry, so we did not have access to a wider sampling of the types they provide. Loftier THC drug-blazon samples were further subdivided into three frequently used vernacular strain categories: Sativa (11), Hybrid (14), and Indica (10) based on information bachelor online (Leafly, 2018; PotGuide.com, 2018; Wikileaf, 2018; Seedfinder, 2020). Cannabis is genetically diverse and based on our research which included 122 samples (Schwabe and McGlaughlin, 2019), and other published research (Gao et al., 2014; Sawler et al., 2015; Lynch et al., 2016; Dufresnes et al., 2017; Soler et al., 2017; Pisupati et al., 2018), the sampling used here adequately captures the genetic variety within and among the groups.
DNA was extracted using a CTAB extraction protocol (Doyle, 1987) modified to apply 0.035–0.100g of dried flower tissue per extraction. Ten variable microsatellite loci developed by Schwabe & McGlaughlin (Schwabe and McGlaughlin, 2019) were used in this study following their previously described procedures.
GENALEX ver. half-dozen.4.1 (Peakall and Smouse, 2006, 2012; 59, 60) was used to calculate pairwise genetic differentiation (FST) and Nei's genetic distance (D) between each of the seven groups and to decide the presence of private alleles. PCoA eigenvalues calculated in GENALEX were used to plot the PCoA in RStudio with the ggplot parcel (R Studio Team, 2015) with 95% confidence interval ellipses.
Genotypes were analyzed using the Bayesian cluster analysis program Structure ver. 2.4.2 (Pritchard et al., 2000). Fire-in and run-lengths of 50,000 generations were used with ten contained replicates for each Construction analysis, testing K=1–10. The number of genetic groups for the data set was determined by Construction HARVESTER (Earl and vonHoldt, 2012), which implements the method of Evanno et al. (2005).
Maverick v1.0.5 (Verity and Nichols, 2016) was used equally an additional verification of Bayesian clustering analysis using thermodynamic integration to determine the advisable number of genetic groups. The following parameters were used: admixture parameter (alpha) of 0.03 with a standard deviation (alphaPropSD) of 0.008, ten replicates (mainRepeats), 1,000 Fire-in iterations (mainBurnin), v,000 sample iterations (mainSamples), 100 TI rungs (thermodynamicRungs), 500 TI Burn-in iterations (thermodynamicBurnin), and one,000 TI iterations (thermodynamicSamples).
Results
Our analyses examined the genetic differentiation and construction of samples from seven Cannabis groups (Supplementary Tabular array one): (1) Wild hemp – feral wild collected hemp; (2) Cultivated hemp – obtained from hemp cultivators; (iii) NIDA – "research course marijuana" samples obtained from NIDA classified as high THC or high THC/CBD; (4) high CBD – drug-blazon Cannabis with relatively high levels of CBD and low levels of THC; and commercially available loftier THC drug-type Cannabis described as (5) Sativa, (6) Hybrid, or (7) Indica. With the exception of genetic altitude statistics, the analyses were performed on samples at the private level, where the genetic placement of each sample is determined independent of its' putative Cannabis group. Conducting analyses at an individual level controls for biases that might arise due to the bogus nature of named groups and varying grouping sample sizes. Clustering (PCoA) and proportion of genetic assignment (STRUCTURE) analyses are presented first by assigning each sample past color to either hemp type or drug type (Figures 1, ii; Supplementary Figure one), every bit these take previously been shown to separate well using genetic information (Datwyler and Weiblen, 2006; Piluzza et al., 2013; Sawler et al., 2015; Lynch et al., 2016; Dufresnes et al., 2017). The aforementioned analyses are then presented by color consignment to i of the 7 subcategories to decide further possible relationships within and among these groups (Figures 3, 4).
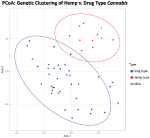
Figure 1. Principal coordinates assay of genetic distance among samples. Samples clustering together are more than closely related. The ellipses represent 95% conviction intervals for each group (Cultivated hemp = orange, Wild hemp = yellow, NIDA = bluish, Loftier CBD = pinkish, Sativa = red, Hybrid = green, Indica = majestic). Approximately 24% of the genetic variation in these groups is shown (Axis 1 = 13.02% and Axis 2 = xi.17%).
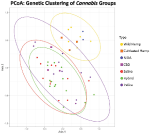
Figure 2. Principal Coordinates Analysis of genetic distance among samples. Samples clustering together are more closely related. The ellipses correspond 95% confidence intervals for each group (Cultivated hemp = orangish, Wild hemp = yellow, NIDA = blue, High CBD = pinkish, Sativa = cerise, Hybrid = green, Indica = purple). Approximately 24% of the genetic variation in these groups is shown (coordinate 1= 13.02% and coordinate two = 11.17%). No confidence intervals were drawn for NIDA, High CBD, or Cultivated Hemp samples due to the small sample size (n = 2, n = three, and north = 3, respectively).
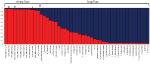
Figure 3. Bayesian clustering assay from Construction with the proportion of inferred beginnings for two genetic groups (Chiliad=2) sorted by proportion of genotype consignment. Each individual is represented equally a single bar in the graph. The NIDA samples are indicated by a green dot. * "Durban Poison" is a drug type assigned 0.95 to hemp ancestry. The messages preceding the sample proper name relate to the category the sample was place in (WH, wild hemp; CH, cultivated hemp; CBD, high CBD drug type; S, sativa drug type; H, hybrid drug type; I, Indica drug type).

Figure 4. Bayesian clustering analysis from STRUCTURE with the proportion of inferred ancestry for ii genetic groups (K=2, top), and for three genetic groups (Grand=3, bottom), Each individual is represented as a single bar in the graph.
Genetic Analyses: Individual Level
Hemp V. Drug Types
Main coordinate analysis (PCoA) with 95% confidence interval ellipses around the hemp-type (cherry-red) and drug-type (blueish) groups shows articulate separation of hemp samples from the drug types. NIDA samples are indicated in green and cluster within the hemp confidence interval (Effigy i). Coordinate ane explains 13.02% of the genetic variation, and an additional 11.17% of the genetic variation is explained by coordinate 2.
STRUCTURE was used to examine sample assignment to genetic groups while assuasive admixture. The appropriate number of Structure groups from K=1–10 was validated using Structure HARVESTER (Earl and vonHoldt, 2012), which had high support for ii genetic groups (K=2, ∆1000=61.35). An additional genetic structure analysis (MAVERICK 1.0.5: Verity and Nichols, 2016) was conducted to independently exam grouping assignments and verified strong support for two genetic groups with the same assignment of individuals (K=2, probability 0.999, data non shown). The two genetic grouping Structure analysis (Effigy 3) shows consistent differentiation between hemp-type and drug-type Cannabis. All hemp samples were assigned a genetic proportion of inferred beginnings (Q) greater than 0.92 (hemp mean group i, Q=0.96). All but two drug-type samples showed admixture associated with hemp <0.78 (range 0.03–0.78) with 31 of 38 (83%) samples <0.50 proportion of ancestry associated with hemp genetic point.
Categorical Group Analysis
Principal coordinate analysis with 95% confidence interval ellipses around the major groups shows that at that place is clear separation of hemp samples from the drug types, with NIDA samples (green) clustering within the hemp conviction interval (Figure 2). The drug-type samples (Indica, Sativa, Hybrid, and high CBD) all occupy the aforementioned character space, singled-out from hemp.
For the categorical group Structure analyses, the two genetic group STRUCTURE analysis (K2, Figure 4) shows consistent differentiation between hemp- and drug-blazon samples. All hemp samples were assigned to genetic group i (yellow) with a proportion of inferred beginnings (Q) greater than 0.93 (hemp mean group 1, Q=0.96). High THC drug-blazon samples showed some admixture with 29 of 35 samples having the bulk of the genetic signal assigned to genetic group two (green; high THC drug-type mean group 2, Q=0.75). The three high CBD drug-type samples were assigned with a hateful of 0.61 to group 1 and 0.39 to groups 2. NIDA samples were assigned to genetic group 1 (NIDA mean grouping 1, Q=0.97), demonstrating a strong genetic association with hemp in this analysis.
Although not strongly supported, the iii genetic group STRUCTURE analysis (K3, Effigy 4) shows some additional genetic construction amongst drug-type samples. All hemp-type samples were assigned to genetic group 1 (yellow) with a proportion of inferred ancestry (Q) greater than 0.ninety (hemp hateful grouping 1, Q=0.93). The loftier THC drug-type samples demonstrated some admixture with 12 of 35 samples assigned genetic signal Q=>0.50 to grouping 2 (green; high THC drug-blazon mean group 2, Q=0.33), and 21 of 35 samples assigned genetic signal Q=>0.50 to grouping iii (purple; high THC drug-type hateful grouping three, Q=0.53). The 3 loftier CBD drug-type samples were assigned with a mean of 0.34 to group i, 0.ten to group ii and 0.58 to group 3. NIDA samples were assigned to genetic group ane (NIDA mean group 1, Q=0.95) with similarly depression betoken from groups 2 and 3 (0.03 and 0.02 respectively) demonstrating a potent genetic association with hemp. Structure analysis results are also presented from Yard=2–10 (Supplementary Effigy 1).
Genetic Analyses: Population Level
Genetic Differentiation
Pairwise genetic differentiation (Fst and Nei'south D) calculated in GENALEX ver. vi.4.1 [59, sixty] institute the highest level of divergence between NIDA and high CBD drug blazon (Fst=0.394) and betwixt hemp and Sativa high THC drug blazon (Nei'due south D=i.026; Tabular array 1). The least divergence was observed among the high THC drug types (Fst=0.023–0.039; Nei's D=0.066–0.102).

Table 1. Pairwise Fst values (below the diagonal) and Nei'southward D (above the diagonal) for major Cannabis groups.
Private Alleles
Individual alleles, alleles found merely in a single group, are commonly used in population genetic studies to place divergent groups. Eight of the x utilized loci independent at least ane private allele in ane Cannabis grouping (Tabular array 2). Wild hemp contained the most individual alleles, 12, while the high CBD group independent only 1. Given that we only sampled two NIDA individuals, the four observed individual alleles indicate that this group contains unique genetic signal.

Table 2. Private alleles in each categorical grouping for ten loci. The number in parentheses after the locus name is number total number alleles for a locus.
Discussion
The purpose of this study was to examine the genetic relationship of Cannabis samples from each of the common categories and subgroups and to determine where NIDA samples autumn on the Cannabis genetic spectrum. The genetic regions used in this report were designed to target non-coding regions of the genome, and therefore less likely to reverberate artifacts related to recent human pick. Our results clearly demonstrate that NIDA Cannabis samples are essentially genetically unlike from nearly commercially available drug-type strains and share a genetic analogousness with hemp samples in several of the analyses. We practice not claim that NIDA is supplying hemp for Cannabis research, rather we are confident that our analyses show that the "research grade marijuana" supplied by NIDA is genetically different from the retail drug-blazon samples analyzed in this study. Previous enquiry has plant that medical and recreational Cannabis from California, Colorado, and Washington differs significantly in cannabinoid levels from the "enquiry course marijuana" supplied by NIDA (Vergara et al., 2017). This investigation adds to the previous research, indicating that the sampled NIDA Cannabis is also genetically distinctive from commercially bachelor medical and recreational Cannabis. Given both this genetic and previous chemotypic investigations have concluded that NIDA is supplying product that does not align with what is available for consumers, our hope is that the NIH and NIDA will support the cultivation of Cannabis that is representative of what medical and recreational consumers are using. Medical practitioners, researchers and patients deserve access to Cannabis products that are comparable to products available on the legal market.
The genetic data collected in this study indicate that ii major genetic groups be inside Cannabis sativa (Figures 1, 3). These results contribute to the growing consensus that hemp- and drug-type Cannabis tin can be consistently differentiated (Forapani et al., 2001; Datwyler and Weiblen, 2006; McPartland, 2006; Hakki et al., 2007; Sawler et al., 2015; Lynch et al., 2016; Dufresnes et al., 2017; Soler et al., 2017), but all Cannabis groups are currently considered a single species that has been selected for different uses. Some admixture of the hemp-blazon genetic bespeak is seen in many of the drug-type samples; this is not unexpected as the legal definition of hemp (0.iii% total THC by dry weight) is non biologically significant and therefore holds no scientific basis for formal taxonomic separation. To our noesis, this written report and collaborative work investigating the genomic Cannabis data (Vergara et al., 2021) are the first to include "research grade marijuana" from NIDA. The placement of NIDA samples with hemp in multiple analyses was unexpected. However, it is important to annotation that some drug-blazon samples (eastward.g., "Durban Poison," Figure iii) are as well placed in the hemp-type genetic group. This finding supports that although at that place are two singled-out Cannabis genetic groups (hemp type and drug type), some strains within those groups have been selected to have the characteristics that we do not commonly associate with their specific genetic background. Crosses betwixt hemp-type and drug-type strains may have been intentional, such every bit the recently adult high CBD drug strains that have low THC concentrations or the development of auto-flowering drug strains that flower as a function of historic period rather than photoperiod, which is a trait historically seen in some hemp varieties (Punja et al., 2017). Additionally, about Cannabis strains are a product of clandestine convenance in underground markets, and so their presumed lineage may non match their actual genetic group. Hence, the finding that NIDA samples belong in the hemp-type genetic group in several analyses does not brand these samples hemp, but it does demonstrate that they are unlike than the majority of drug-blazon Cannabis found in the marketplace.
Analyses were likewise conducted to examine how NIDA samples relate to traditionally recognized subgroups of Cannabis. It is of import to note that some of the subgroups we assigned samples to are largely artificial and were based on information provided by online databases, which is the information that a recreational or medical consumer would have admission to (Leafly, 2018; PotGuide.com, 2018; Wikileaf, 2018; Seedfinder, 2020). Although the categories Sativa, Indica and Hybrid are oft used in the Cannabis industry and among consumers, researchers have withal to find consequent phenotypic and/or genotypic traits driving these widely referenced categories (Hillig, 2005; McPartland, 2017; McPartland and Guy, 2017; McPartland and Modest, 2020). Given the loftier degree of intentional hybridization amid drug-type Cannabis, it stands to reason that nosotros would not see clear genetic separation amidst these categories. Additionally, the growing interest in Cannabis with alternative combinations of cannabinoids other than THC has led to increased breeding efforts between hemp and drug types, farther diluting any historical genetic distinctions that might have existed. Therefore, we did not expect the vii groups nosotros used here to resolve as genetically unique. The analyses of genetic distance (Tabular array one) and private alleles (Table ii) support that NIDA samples are substantially diverged from all other Cannabis groups, including hemp, and incorporate a unique genetic profile. The high CBD drug-blazon samples are genetically more divergent from the hemp group than the high THC drug-type groups, suggesting that these are hybrids of hemp-type and high THC drug-type Cannabis. Additionally, the high CBD drug-type samples and several drug-type samples are admixed with some genetic signal assigned to both hemp and drug groups. Given the intentional breeding of different Cannabis groups and the fact that hemp-blazon and drug-type Cannabis are defined past total THC content, a trait under selection, the lack of genetic support for many distinct groups is not surprising.
The Academy of Mississippi National Middle for Natural Products Research (NCNPR) produces research grade drug-type Cannabis for NIDA. NCNPR does not provide diverseness or strain information when filling Cannabis orders, so it is unclear what is currently grown for federally funded Cannabis research. Our data advise that the NIDA Cannabis analyzed in this study was sourced from a unmarried strain or two very closely related strains inside the NCNPR stock. Without additional information well-nigh NCNPR Cannabis product, information technology is difficult to know how many strains are provided for federally funded enquiry using Cannabis from NIDA. This study included only two Cannabis samples from NIDA which limits what nosotros can conclude about the latitude of genetic variety contained in NIDA collections. The inclusion of additional NIDA samples would be beneficial, but additional sampling would in no way change the genotypes of the samples included in this study, which was supplied to researchers conducting federally approved Cannabis research. Although the sample size of NIDA samples could bear upon their placement in group-based analyses of genetic distance (Tabular array 1), all other analyses were carried out at an individual level (Figures one–four, and Supplemental Figure 1) to avoid this upshot. The exact crusade of the genetic stardom in NIDA samples cannot be determined, merely many factors could play a role such as directional selection, inbreeding, sourcing of ancestral strains non currently represented in the commercial marketplace, and/or cross-pollination from wild or cultivated hemp. It is our promise that this report will inspire further investigation of additional cloth supplied by NIDA.
Our written report indicates the need for additional research and refinement of our understanding of Cannabis genetic structure and how those differences might impact Cannabis consumers. Every bit the need for medical Cannabis increases, it is important that research examining the threats and benefits of Cannabis use accurately reflects the experiences of the general public.
Given the apace changing landscape of Cannabis regulation and consumption (ProCon, 2018a,b), it is non surprising that commercially bachelor Cannabis contains a variety of genetic types. Commercially available Cannabis has come up to market through non-traditional means leading to many inconsistencies. We have previously documented (Schwabe and McGlaughlin, 2019) that there is substantial genetic difference amidst samples inside named strains, which only exacerbates questions almost the impacts of Cannabis consumption. These results emphasize the demand to increase consistency within the Cannabis marketplace, and the need for "research course marijuana" to accurately represent what is accessible to consumers.
This written report highlights the genetic departure betwixt "research grade marijuana" provided by NIDA and commercial Cannabis available to medical and recreational users. Hence, research conducted with NIDA Cannabis may not be indicative of the furnishings that consumers are experiencing. Additionally, research has demonstrated that Cannabis distributed past NIDA has lower levels of the primary medicinal cannabinoids (THC and CBD) and college levels of the THC degradation product cannabinol (CBN; Vergara et al., 2017). Taken together, these results demonstrate the need for there to be a greater diversity of Cannabis bachelor for medical research and that the genetic provenance of those samples to be established to fully understand the implications of results.
Data Availability Argument
The original contributions presented in the report are included in the commodity/Supplementary Fabric, farther inquiries tin can be directed to the corresponding authors.
Author Contributions
As conceived the project, collected the samples, conducted Dna extractions, designed and optimized microsatellite primers, compiled and analyzed the data, and drafted manuscript content. CH conducted DNA extractions, compiled and analyzed the data, and prepared the outset draft of the manuscript. RH provided DNA from the NIDA samples. MM directed the project, provided some funding, and contributed to statistical assay and manuscript revisions. All authors contributed to the article and canonical the submitted version.
Funding
The University of Northern Colorado Graduate Student Association and the Gerald Schmidt Memorial Biology Scholarship awarded grants providing fractional funding for this project. Funding was also obtained from the Academy of Northern Colorado School of Biological Sciences. These funding sources did not play any roles in the development, design, execution, or assay of this study, nor did they contribute to the writing of the manuscript and had no input in the decision to publish this research.
Conflict of Involvement
The authors declare that the research was conducted in the absence of whatsoever commercial or financial relationships that could exist construed as a potential conflict of interest.
Publisher's Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this commodity, or merits that may be fabricated by its manufacturer, is non guaranteed or endorsed by the publisher.
Acknowledgments
The National Institute on Drug Abuse provided the Research Grade Cannabis samples from which Dna used in this report was extracted. We thank Matt Kahl and Caren Kershner for providing hemp samples for this projection, Melissa Islam, Associate Director of Biodiversity Research at the Denver Botanic Gardens for access to wild collected hemp herbarium specimens (Kathryn Kalmbach Herbarium), and the Cannabis Genome Enquiry Initiative for the sample of Cannabis ruderalis. Funding for this project was provided through research grants awarded to A. Schwabe by the University of Northern Colorado Graduate Student Association and the University of Northern Colorado College of Natural and Heath Sciences, and the McGlaughlin Lab, Schoolhouse of Biological Sciences, University of Northern Colorado. Nosotros capeesh and are grateful to Samantha Naibauer and Emily Schumacher for assisting with the figures. Many thank you to Nolan Kane who provided feedback and support for this research. Finally, cheers Daniela Vergara for providing feedback and support for this enquiry, and on the manuscript preparation.
Supplementary Material
The Supplementary Cloth for this commodity tin can be institute online at: https://www.frontiersin.org/manufactures/10.3389/fpls.2021.675770/full#supplementary-material
References
Abel, East. 50. (2013). Marihuana: The First Twelve Thousand Years. New York, NY: Springer Scientific discipline & Concern Media.
Google Scholar
Backes, M., and Weil, A. (2014). Utilize of Medicinal Cannabis. In Cannabis Pharmacy: The Practical Guide to Medical Marijuana. Black Dog & Leventhal, 230. New York.
Google Scholar
Baron, E. P. (2018). Medicinal backdrop of cannabinoids, terpenes, and flavonoids in Cannabis, and benefits in migraine, headache, and pain: an update on electric current evidence and Cannabis science. Headache 58, 1139–1186. doi: ten.1111/head.13345
PubMed Abstract | CrossRef Full Text | Google Scholar
Borgelt, 50. M., Franson, K. 50., Nussbaum, A. M., and Wang, G. Southward. (2013). The pharmacologic and clinical effects of medical cannabis. Pharmacotherapy: The Periodical of Man Pharmacology and Drug Therapy. 33, 195–209. doi: ten.1002/phar.1187
PubMed Abstract | CrossRef Full Text | Google Scholar
Citti, C., Braghiroli, D., Vandelli, M. A., and Cannazza, One thousand. (2018). Pharmaceutical and biomedical analysis of cannabinoids: a critical review. J. Pharm. Biomed. Anal. 147, 565–579. doi: x.1016/j.jpba.2017.06.003
PubMed Abstract | CrossRef Full Text | Google Scholar
Clarke, R. C., and Merlin, M. D. (2013). Cannabis: Evolution and Ethnobotany. Berkeley: University of California Press.
Google Scholar
Clarke, R. C., and Merlin, Thou. D. (2015). Letter to the editor: small, ernest. 2015. Evolution and classification of Cannabis sativa (marijuana, hemp) in relation to human utilization. Bot. Rev. 81, 295–305. doi: 10.1007/s12229-015-9158-ii
CrossRef Full Text | Google Scholar
Cousijn, J., Nunez, A. Due east., and Filbey, F. 1000. (2018). Fourth dimension to admit the mixed furnishings of cannabis on health: a summary and critical review of the NASEM 2017 study on the wellness effects of cannabis and cannabinoids. Addiction 113, 958–966. doi: 10.1111/add.14084
PubMed Abstruse | CrossRef Full Text | Google Scholar
Datwyler, Due south. L., and Weiblen, G. D. (2006). Genetic variation in hemp and marijuana (Cannabis sativa Fifty.) according to amplified fragment length polymorphisms. J. Forensic Sci. 51, 371–375. doi: x.1111/j.1556-4029.2006.00061.10
PubMed Abstract | CrossRef Full Text | Google Scholar
de Meijer, E. P. M., Vanderkamp, H. J., and Vaneeuwijk, F. A. (1992). Characterization of Cannabis accessions with regard to cannabinoid content in relation to other found characters. Euphytica 62, 187–200. doi: 10.1007/BF00041753
CrossRef Full Text | Google Scholar
Doyle, J. J. (1987). A rapid Dna isolation procedure for small quantities of fresh leafage tissue. Phytochemi. Bulletin four, 359–361.
Google Scholar
Drug Enforcement Assistants and Department of Justice (2016). Applications to go registered under the controlled substances act to manufacture marijuana to supply researchers in the United states of america. Policy statement. Fed. Regist. 81, 53846–53848.
PubMed Abstruse | Google Scholar
Dufresnes, C., Jan, C., Bienert, F., Goudet, J., and Fumagalli, L. (2017). Broad-calibration genetic diverseness of Cannabis for forensic applications. PLoS One 12:e0170522. doi: ten.1371/journal.pone.0170522
PubMed Abstract | CrossRef Full Text | Google Scholar
Earl, D. A., and vonHoldt, B. G. (2012). Construction HARVESTER: a website and programme for visualizing STRUCTURE output and implementing the Evanno method. Conserv. Genet. Resour. 4, 359–361. doi: 10.1007/s12686-011-9548-7
CrossRef Full Text | Google Scholar
ElSohly, Yard. A. (2007). Marijuana & the Cannabinoids. Totowa, New Jersey: Humana Press.
Google Scholar
Evanno, G., Regnaut, S., and Goudet, J. (2005). Detecting the number of clusters of individuals using the software Structure: a simulation study. Mol. Ecol. xiv, 2611–2620. doi: 10.1111/j.1365-294X.2005.02553.x
PubMed Abstruse | CrossRef Full Text | Google Scholar
Ferber, Due south. One thousand., Namdar, D., Hen-Shoval, D., Eger, G., Koltai, H., Shoval, M., et al. (2020). The "entourage issue:" terpenes coupled with cannabinoids for the treatment of mood disorders and feet disorders. Curr. Neuropharmacol. 18, 87–96. doi: 10.2174/1570159X17666190903103923
PubMed Abstract | CrossRef Total Text | Google Scholar
Forapani, Due south., Carboni, A., Paoletti, C., Cristiana, Five. M., Ranalli, North. P., and Mandolino, Thousand. (2001). Comparison of hemp varieties using random amplified polymorphic DNA markers. Ingather Sci. 41, 1682–1689. doi: 10.2135/cropsci2001.1682
CrossRef Full Text | Google Scholar
Gao, C. S., Xin, P. F., Cheng, C. H., Tang, Q., Chen, P., Wang, C. B., et al. (2014). Diversity assay in Cannabis sativa based on large-scale development of expressed sequence tag-derived uncomplicated sequence repeat markers. PLoS One 9:e110638. doi: x.1371/journal.pone.0110638
PubMed Abstruse | CrossRef Full Text | Google Scholar
Hakki, Eastward. E., Kayis, S. A., Pinarkara, E., and Sag, A. (2007). Inter simple sequence repeats carve up efficiently hemp from marijuana (Cannabis sativa L.). Electron. J. Biotechnol. x, 570–581. doi: 10.2225/vol10-issue4-fulltext-4
CrossRef Full Text | Google Scholar
Heilig, S. (2011). The pot volume: a complete guide to Cannabis, its office in medicine, politics, scientific discipline, and civilization. J. Psychoactive Drugs 43, 76–77. doi: 10.1080/02791072.2011.566505
CrossRef Total Text | Google Scholar
Hillig, Thousand. W. (2005). Genetic evidence for speciation in Cannabis (Cannabaceae). Genet. Resour. Crop. Evol. 52, 161–180. doi: 10.1007/s10722-003-4452-y
CrossRef Full Text | Google Scholar
Jikomes, N., and Zoorob, Grand. (2018). The cannabinoid content of legal cannabis in Washington state varies systematically beyond testing facilities and popular consumer products. Sci. Rep. 8:4519. doi: ten.1038/s41598-018-22755-ii
PubMed Abstract | CrossRef Full Text | Google Scholar
Lynch, R. C., Vergara, D., Tittes, S., White, K., Schwartz, C. J., Gibbs, M. J., et al. (2016). Genomic and chemical diversity in Cannabis. Crit. Rev. Plant Sci. 35, 349–363. doi: 10.1080/07352689.2016.1265363
CrossRef Full Text | Google Scholar
McPartland, J. M. (2006). Commentary on: Datwyler SL, Weiblen GD. Weiblen. Genetic variation in hemp and marijuana (Cannabis sativa L.) according to amplified fragment length polymorphisms. J. Forensic Sci. 51:1405. doi: 10.1111/j.1556-4029.2006.00276.10
PubMed Abstract | CrossRef Full Text | Google Scholar
McPartland, J. M. (2017). "Cannabis sativa and Cannabis indica versus "Sativa" and "Indica"," in Botany and Biotechnology. eds. South. Chandra, H. Lata, and G. ElSohly (Cham: Springer).
Google Scholar
McPartland, J. 1000., and Guy, G. West. (2017). Models of Cannabis taxonomy, cultural bias, and conflicts between scientific and vernacular names. Bot. Rev. 83, 327–381. doi: x.1007/s12229-017-9187-0
CrossRef Full Text | Google Scholar
McPartland, J. K., and Small, E. (2020). A classification of endangered high-THC cannabis (Cannabis sativa subsp. indica) domesticates and their wild relatives. Phytokeys 144, 81–112. doi: 10.3897/phytokeys.144.46700
PubMed Abstract | CrossRef Full Text | Google Scholar
Nahler, Chiliad., Jones, T., and Russo, E. (2019). Cannabidiol and contributions of major hemp phytocompounds to the "entourage event;" possible mechanisms. J. Altern. Complement. Int. Med. 5:070. doi: 10.24966/ACIM-7562/100066
CrossRef Full Text | Google Scholar
Peakall, R., and Smouse, P. E. (2006). GENALEX 6: genetic assay in excel. Population genetic software for pedagogy and research. Mol. Ecol. Notes 6, 288–295. doi: 10.1111/j.1471-8286.2005.01155.x
CrossRef Full Text | Google Scholar
Peakall, R., and Smouse, P. East. (2012). GENALEX 6.5: genetic analysis in excel. Population genetic software for education and research-an update. Bioinformatics 28, 2537–2539. doi: 10.1093/bioinformatics/bts460
PubMed Abstruse | CrossRef Full Text | Google Scholar
Piluzza, G., Delogu, G., Cabras, A., Marceddu, S., and Bullitta, S. (2013). Differentiation between fiber and drug types of hemp (Cannabis sativa L.) from a drove of wild and domesticated accessions. Genet. Resour. Crop. Evol. lx, 2331–2342. doi: 10.1007/s10722-013-0001-5
CrossRef Full Text | Google Scholar
Potter, D. J., Clark, P., and Brown, M. B. (2008). Authorisation of delta(nine)-THC and other cannabinoids in Cannabis in England in 2005: implications for psychoactivity and pharmacology. J. Forensic Sci. 53, 90–94. doi: 10.1111/j.1556-4029.2007.00603.x
PubMed Abstract | CrossRef Total Text | Google Scholar
Punja, Z. Thou., Rodriguez, Thou., and Chen, Due south. (2017). "Assessing genetic diversity in Cannabis sativa using molecular approaches," in Cannabis sativa Fifty. - Phytology and Biotechnology. eds. S. Chandra, H. Lata, and M. A. ElSohly (Cham, Switzerland: Springer International Publishing AG), 395–418.
Google Scholar
R Studio Team (2015). R Studio: integrated evolution for R,. RStudio, Inc., Boston, MA.
Google Scholar
Sawler, J., Stout, J. K., Gardner, K. M., Hudson, D., Vidmar, J., Butler, 50., et al. (2015). The genetic construction of marijuana and hemp. PLoS One ten:e0133292. doi: 10.1371/periodical.pone.0133292
PubMed Abstruse | CrossRef Full Text | Google Scholar
Schwabe, A. L., and McGlaughlin, Thousand. E. (2019). Genetic tools weed out misconceptions of strain reliability in Cannabis sativa: implications for a budding industry. J. Cannabis Res. i:332320. doi: ten.1186/s42238-019-0001-ane
PubMed Abstract | CrossRef Full Text | Google Scholar
Small, Due east. (2015). Evolution and classification of Cannabis sativa (marijuana, hemp) in relation to human utilization. Bot. Rev. 81, 189–294. doi: 10.1007/s12229-015-9157-3
CrossRef Full Text | Google Scholar
Pocket-sized, E. (2016). Cannabis: A Complete Guide. Boca Raton, FL: CRC Press.
Google Scholar
Pocket-size, E. (2017). "Classification of Cannabis sativa L. in relation to agronomical, biotechnological, medical and recreational utilization," in Cannabis sativa L. - Botany and Biotechnology. eds. S. Chandra, H. Lata, and M. A. ElSohly (Cham, Switzerland: Springer International Publishing AG), 1–62.
Google Scholar
Pocket-size, E., Jui, P. Y., and Lefkovitch, L. P. (1976). A numerical taxonomic assay of Cannabis with special reference to species delimitation. Syst. Bot. 1, 67–84. doi: 10.2307/2418840
CrossRef Total Text | Google Scholar
Smith, M. H. (2012). Heart of Dankness: Secret Botanists, Outlaw Farmers, and the Race for the Cannabis Cup. New York, NY: Broadway Books.
Google Scholar
Soler, Due south., Gramazio, P., Figas, M. R., Vilanova, S., Rosa, Due east., Llosa, E. R., et al. (2017). Genetic structure of Cannabis sativa var. indica cultivars based on genomic SSR (gSSR) markers: implications for breeding and germplasm management. Ind. Crop. Prod. 104, 171–178. doi: 10.1016/j.indcrop.2017.04.043
CrossRef Full Text | Google Scholar
United States Congress (1970). Comprehensive Drug Abuse Prevention and Control Act of 1970. United States: Public Police force.
Google Scholar
Vergara, D., Baker, H., Clancy, M., Keepers, K. One thousand., Mendieta, J. P., Pauli, C. S., et al. (2016). Genetic and genomic tools for Cannabis sativa. Crit. Rev. Institute Sci. 35, 364–377. doi: 10.1080/07352689.2016.1267496
CrossRef Full Text | Google Scholar
Vergara, D., Bidwell, L. C., Gaudino, R., Torres, A., Du, G., Ruthenburg, T. C., et al. (2017). Compromised external validity: federally produced cannabis does non reflect legal markets. Sci. Rep. 7:1. doi: ten.1038/srep46528
PubMed Abstract | CrossRef Full Text | Google Scholar
Vergara, D., Huscher, E. 50., Keepers, Chiliad. M., Pisupati, R., Schwabe, A. 50., McGlaughlin, M. Eastward., et al. (2021). Genomic evidence that governmentally produced Cannabis sativa poorly represents genetic variation available in state markets. Front end. Plant Sci. [Preprint]. doi: 10.3389/fpls.2021.668315
CrossRef Full Text | Google Scholar
paigequincluddeas.blogspot.com
Source: https://www.frontiersin.org/articles/10.3389/fpls.2021.675770/full
0 Response to "Seedfinder Review for 24 Karat From Dna Genetics"
Post a Comment